| 基于 图神经网络 + 知识图谱 的推荐系统 1 | 您所在的位置:网站首页 › ckg 知识图谱 › 基于 图神经网络 + 知识图谱 的推荐系统 1 |
基于 图神经网络 + 知识图谱 的推荐系统 1
|
ACM2019论文阅读 KGAT: Knowledge Graph Attention Network for Recommendation 1.前言 首先是对于阅读的总结,收集了最近的知识图谱在推荐中的应用,简单分类,先从知识图谱和图神经网络的融合开始.把对于论文的一些总结写在最开始: 动机 1.传统的推荐系统只是将用户的行为作为独立的实例来进行训练模型,但是实体之间是存在很多的高阶的关系的,为了捕获这些高阶的关系,考虑将知识图谱和 用户-项目图进行融合,对传统的协同过滤进行一些补充 2.传统的混合方式有两种,基于路径的以及基于规则的 基于路径的: 两个节点之间的大量路径的处理方式 路径选择算法:没有针对推荐目标进行优化 定义元路径选择突出路径:需要领域知识 基于规则的: 设计额外的损失来捕获知识图谱结构来正则化推荐模型 存在的问题:以隐式的方式对知识图谱进行编码核心思想: 将用户-项目二部图 和 知识图谱融合 对融合后的知识图谱进行嵌入表示 使用attention机制,递归的传播邻居节点的嵌入表示,更新当前结点的表示 最后进行用户对项目的评分预测结论: 1.对比已有的方法,推荐效果有所提升 2.论文中实际的双向聚合函数,比传统的聚合方式效果要好 3.在考虑2-3跳的邻居信息时,模型的效果最好 4.TransR嵌入以及attention模块均对模型有正向的影响.假设: 观测到的样本和为观测的样本差异最大(未观测的样本是负样本) 2.模型实现 2.1 任务描述对于模型中用到的一些概念以及模型的任务进行描述 用户商品二部图: 使用二部图的方式表示用户和商品的交互记录 yui = 1表示有交互 yui = 0表示没有交互知识图谱: 物品的边的信息 使用 主体-属性-对象 组成的有向图 形式化的表示为(h,r,t) 表示头部实体h和尾部实体t之间存在r关系 以及一个项目-实体对齐集合a=(i,e) 表示项目i可以和实体e对齐协同知识图谱(CKG) 将用户行为和项目知识编为一个统一的知识图谱 使用三元组表示用户行为: (u,Interact,i) yui表示用户u和i的交互关系 然后使用项目实体对齐集合,最终将user-item图和KG集成为一个图 表示为: G = {(h,r,t)|h,t∈E′,r∈R′}where E′= E∪U and R′= R∪{Interact} 即两个实体(h,t)间存在r关系进行关联,E'是原来的实体集和用户集的并集,R'是原有的知识图谱关系集R和用户行为集的并集任务描述: 输入: 协同知识图谱G,包含user-item二部图G1以及知识图G2 输出: 一个预测函数,用于预测用户u采用项目i的概率高阶连接: 节点间存在的l阶路径 对于传统的连接方式 CF基于用户行为连接 FM NFM等SL模型关注基于属性的连接 向用户推荐具有相似属性的项目 但是无法连接高阶的连通性,例如下图中项目1和项目2之间通过属性e1连接,但是这种高阶的关系无法被学得
模型主要由三部分组成: 1.嵌入层 保持CKG结构,将节点embedding 2.注意力嵌入传播层 递归的传播来自节点邻居的嵌入内容,更新表示,传播的过程中使用注意力机制 3.预测层 传播层的用户表示和项表示聚合起来,并输出预测的匹配分数下面对每一部分进行解释 2.2.1 Embedding Layer
知识图谱嵌入: 将实体和关系参数化为向量的有效方法,保持知识图的结构 作者使用的是TransR[19]进行训练主要的思路: 对于一个知识图谱的表示(h,r,t),使用下面的假设进行训练:
损失函数的设计: 损失函数基于的假设是: 有效的三元组和无效的三元组之间的置信得分差异最大化,无效三元组g(h,r,t')是通过随机替换有效三元组的一个实体得到.
在GCN[17]的基础上,沿着高阶连通性,递归传播嵌入信息 同时使用图注意力网络[28]的思想,生成注意力权值,来描述连接的重要性
这一层的结构如上图所示,主要分为三个部分 信息传播、知识认知注意力和信息聚合 信息传播部分: 同一个实体能够参与多个三元组,并且可以充当两个三元组的桥梁来传播信息,对于下面的一组示例:
在训练时,首先获取一个实体为头部的全部三元组,组成ego-network[21]:
此时,可以使用ego-network的线性组合来表示实体h的一阶连通结构:
Knowledge-aware Attention: 衰减因子的实现机制是:
然后使用softmax函数对与h相连的系数进行归一化:
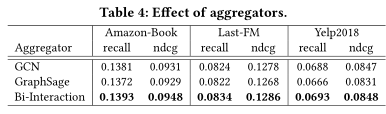
Information Aggregation: 最后将实体的表示形式eh和ego-network聚合为实体h的新的表示形式,使用三种类型的聚合器实现:前两种是已有的聚合器,最后一种是作者提出的聚合器: 1.GCN Aggregator: 将两种表示形式相加并进行非线性变换
2.GraphSage Aggregator: 连接两个表示,然后是一个非线性变换
3.Bi-Interaction Aggregator: 考虑eh和eNh之间的两种特征交互
其中激活函数为:
High-order Propagation: 单一的传播已经介绍完成,可以堆叠更多的传播层来探索高阶连通性信息,收集从更高跳邻居传播的信息
对于l-1阶的表示,能够存储来自l-1跳邻居的信息 2.2.3 model prediction对于用户u以及项目i的多阶表示: {eu(1),...,eu(l)}由于第l层的输出是深度为l,根为u的树的消息聚合,如2.2.2的图所示 采用层聚合机制,将每一步的表示连接成单个向量
这样可以通过嵌入传播来丰富初始嵌入,并通过调整l控制传播强度 最终的用户得分为:
模型的优化使用BPR损失[22] 它假设观察到的交互比未观察到的交互具有更高的预测值,这些交互表明了更多的用户偏好:
总的损失函数为:
θ是模型的参数集 训练方式: 交替优化LKG 和 LCF 优化器使用Adam 首先对于一批随机抽样的知识图谱样本(h,r,t,t'),更新所有节点的嵌入; 然后随机采样一批(u,i,j),传播L步后检索他们的表示,利用预测损失的梯度更新模型参数 3.模型验证从三部分对模型进行验证 1.How does KGAT perform compared with state-of-the-art knowledge-aware recommendation methods? 和先进的方法对比 2.How do different components (i.e., knowledge graph embedding, attention mechanism, and aggregator selection) affect KGAT? 对比三种聚合函数 3.Can KGAT provide reasonable explanations about user preferences towards items? 对于用户偏好的解释能力 3.1 Dataset Description在三个数据集上进行评估 Amazon-book 书籍推荐 Last-FM 音乐推荐 Yelp2018 餐馆和酒吧等视为item需要为每一个数据集构建知识 对于Amazon-book和Last-FM,我们遵循[40]中的方法 如果有可用的映射,则通过标题匹配将条目映射到Freebase实体。考虑与项目对其的实体直接相关的三元组 同时还考虑了两跳的邻居三元组 对于Yelp2018,我们从本地商业信息网络中提取项目知识(如类别、位置和属性)作为KG数据。对三个知识图谱,取出数据集中出现频率低的实体,对于每个数据集,随机选择80%作为训练集,其余是测试集 对于交互数据,每一个交互过的实例,随机抽取一个未消费过的负物品配对 3.2 问题1的性能比较
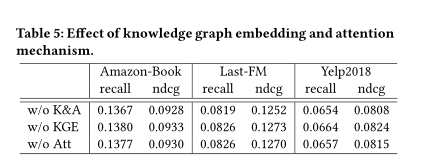
分别从层数 聚合器 知识图谱嵌入和注意力机制的影响 3.3.1传播深度在不同的传播深度下,模型的效果验证
通过禁用KGAT-1的几个部分来进行研究 TransR嵌入部分 KGAT-1w/o kge 注意力机制改为 1/|Nh| KGAT-1w/o Att 两部分都去掉 KGAT-1w/o k&A
|



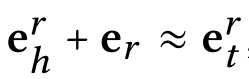
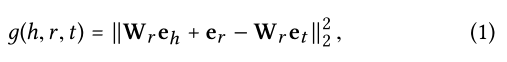
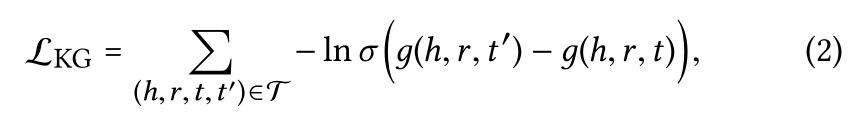

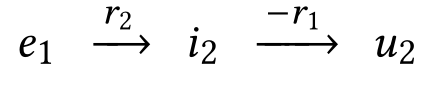
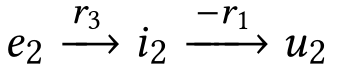
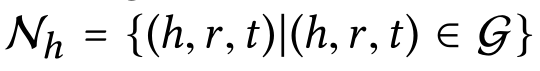
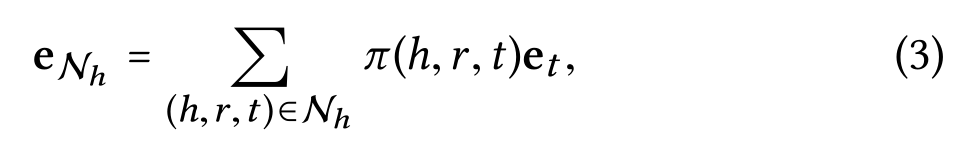
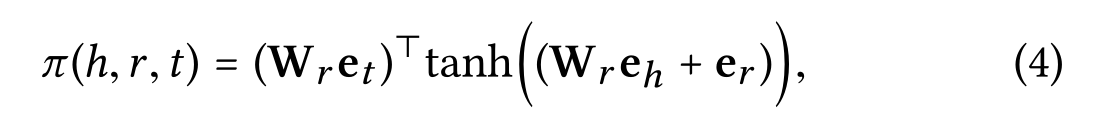
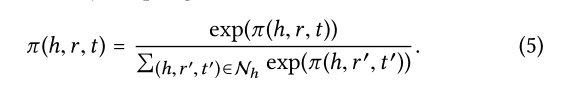
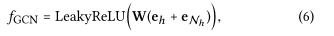
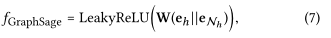
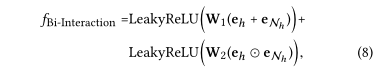
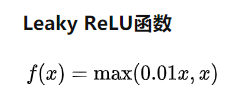
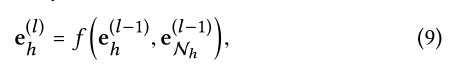
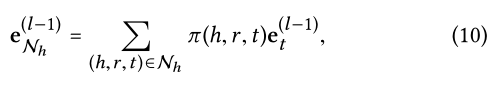
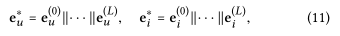

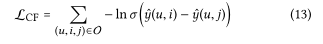
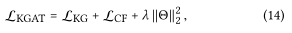
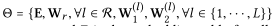


【本文地址】